node.js基础
node.js 语法
 最近一段时间在用node.js做一个web项目(JMarketPlace),以前的印象是javascript是一种前端语言,但是在接触到backbone和node.js后,彻底更新了我对javascript的观念,它真的很强大,在这一项目中,从前端到后端都是用的javascript,对于我不得不说这是一次挑战。在开始这个项目之前没有接触过node.js,在项目中需要用到什么就是查,虽然走了一些弯路但是还是在磕磕碰碰中走过来了,这里我想对node.js进行总结。官方给出了如下定义:
最近一段时间在用node.js做一个web项目(JMarketPlace),以前的印象是javascript是一种前端语言,但是在接触到backbone和node.js后,彻底更新了我对javascript的观念,它真的很强大,在这一项目中,从前端到后端都是用的javascript,对于我不得不说这是一次挑战。在开始这个项目之前没有接触过node.js,在项目中需要用到什么就是查,虽然走了一些弯路但是还是在磕磕碰碰中走过来了,这里我想对node.js进行总结。官方给出了如下定义:
Node.js is a platform built onChrome’s JavaScript runtimeforeasily building fast, scalable network applications. Node.js uses anevent-driven, non-blocking I/O model that makes it lightweight and efficient,perfect for data-intensive real-time applications that run across distributed devices.
异步式I/O与事件驱动
Node.js最大的特点就是采用异步式I/O与事件驱动的架构设计。对于高并发的解决方案,传统的架构是多线程模型,也就是为每个业务逻辑提供一个系统线程,通过系统线程切换来弥补同步式I/O调用时的时间开销。Node.js 使用的是单线程模型,对于所有I/O 都采用异步式的请求方式,避免了频繁的上下文切换。Node.js 在执行的过程中会维护一个事件队列,程序在执行时进入事件循环等待下一个事件到来,每个异步式I/O 请求完成后会被推送到事件队列,等待程序进程进行处理。
例如,对于简单而常见的数据库查询操作,按照传统方式实现的代码如下:
res= db.query('SELECT * from some_table');
res.output();
以上代码在执行到第一行的时候,线程会阻塞,等待数据库返回查询结果,然后再继续处理。然而,由于数据库查询可能涉及磁盘读写和网络通信,其延时可能相当大(长达几个到几百毫秒,相比CPU的时钟差了好几个数量级),线程会在这里阻塞等待结果返回。对于高并发的访问,一方面线程长期阻塞等待,另一方面为了应付新请求而不断增加线程,因此会浪费大量系统资源,同时线程的增多也会占用大量的CPU 时间来处理内存上下文切换,而且还容易遭受低速连接攻击。看看Node.js是如何解决这个问题的:
db.query('SELECT* from some_table', function(res){
res.output();
});
这段代码中db.query 的第二个参数是一个函数,我们称为回调函数。进程在执行到db.query的时候,不会等待结果返回,而是直接继续执行后面的语句,直到进入事件循环。当数据库查询结果返回时,会将事件发送到事件队列,等到线程进入事件循环以后,才会调用之前的回调函数继续执行后面的逻辑。
回调函数
之前使用javascript并不多,所以对回调函数这个机制不是很熟悉,这里将对回调函数进行总结。让我们来想像一个基本场景,我们要干某件耗费大量时间的事,比如试图读取一个大文件,我们不想让Node.js服务必须读完这个文件才能响应别的请求,为了完成这样的功能,我们最好是告诉Node.js在后台读取这个文件,当读取完之后通过某种方式通知我们,而在这个过程中,服务器同时还能处理别的请求,也就是使我们的代码变成“非阻塞”,就像我们刚刚举的例子一样,以适用于同时时间处理多个请求的情况,我们也把这个叫做异步调用。
下面是一个非阻塞文件读取器的代码:
var http = require('http');
var fileSystem = require('fs');
http.createServer(function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
var read_stream = fileSystem.createReadStream('myfile.txt');
read_stream.on('data', writeCallback);
read_stream.on('close', closeCallback);
function writeCallback(data){
response.write(data);
}
function closeCallback(){
response.end();
}
}).listen(8080);
console.log('Server started');
这里我们使用了Node.js内置的文件系统模块,用.createReadStream()读取我们的文件,并绑定两个函到”data”和”close”事件。这些函数将在事件引发时执行。把上述代码存为”fileReader.js”,在同级目录下新建一个文本文件”myfile.txt”,执行”node fileReader.js”命令,现在你可以在http://localhost:8080 看到浏览器里显示了myfile.txt内容了。
调用本地exe应用
Node.js提供了调用本地程序的api(http://nodejs.org/api/child_process.html),这里简单介绍一下exec方法:
child_process.exec(command,[options], callback)
下面是一个小示例:
var exec = require('child_process').exec,
child;
child = exec('cat *.js bad_file | wc -l',
function (error, stdout, stderr) {
console.log('stdout: ' + stdout);
console.log('stderr: ' + stderr);
if (error !== null) {
console.log('exec error: ' + error);
}
});
在回调函数中处理出错信息或者打印正确信息。
node.js web开发
Express框架+Jade引擎模版
npm提供了大量的第三方模块,其中不乏许多Web 框架,我们没有必要重复发明轮子,因而选择使用 Express作为开发框架,因为它是目前最稳定、使用最广泛,而且Node.js 官方推荐的唯一一个 Web开发框架。Express( http://expressjs.com/ ) 除了为 http 模块提供了更高层的接口外,还实现了许多功能,其中包括:
路由控制; 模板解析支持; 动态视图; 用户会话; CSRF 保护; 静态文件服务; 错误控制器; 访问日志; 缓存; 插件支持。
varexpress = require('express');
varapp = express.createServer();
app.use(express.bodyParser());
app.all('/', function(req,res) {
res.send(req.body.title+ req.body.text);
});
app.listen(3000);
可以看到,我们不需要手动编写 req 的事件监听器了,只需加载 express.bodyParser()就能直接通过 req.body 获取 POST 的数据了。
工程的结构
我们回过头来看看Express都生成了哪些文件。除了 package.json,它只产生了两个JavaScript文件app.js和routes/index.js。模板引擎 ejs 也有两个文件 index.ejs和layout.ejs,此外还有样式表 style.css。下面来详细看看这几个文件。App.js是工程的入口Routes/index.js是路由文件,相当于控制器,用于组织展示的内容
exports.index = function(req, res) {
res.render('index', {title: 'Express' });
};
app.js中通过 app.get(‘/’,routes.index); 将“/ ”路径映射到 exports.index函数下。其中只有一个语句 res.render(‘index’, {title: ‘Express’ }),功能是调用模板解析引擎,翻译名为 index 的模板,并传入一个对象作为参数,这个对象只有一个属性,即 title: ‘Express’。PS:title属性是一定要定义的,不然会出错。 Views/index.jade和views/layout.jade是模板文件
工作原理
当通过浏览器访问 app.js 建立的服务器时,会看到一个简单的页面,实际上它已经完成了许多透明的工作,现在就让我们来解释一下它的工作机制,以帮助理解网站的整体架构。访问http://localhost:3000,浏览器会向服务器发送以下请求:
GET / HTTP/1.1
Host: localhost:3000
Connection: keep-alive
Cache-Control: max-age=0
User-Agent: Mozilla/5.0 AppleWebKit/535.19 (KHTML, like Gecko)Chrome/18.0.1025.142
Safari/535.19
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh;q=0.8,en-US;q=0.6,en;q=0.4
Accept-Charset: UTF-8,*;q=0.5
其中第一行是请求的方法、路径和HTTP 协议版本,后面若干行是 HTTP 请求头。app 会解析请求的路径,调用相应的逻辑。app.js 中有一行内容是 app.get(‘/’,routes.index),它的作用是规定路径为“/”的 GET 请求由routes.index 函数处理。routes.index通过res.render(‘index’, { title:’Express’ }) 调用视图模板 index,传递 title变量。最终视图模板生成HTML 页面,返回给浏览器,返回的内容是:
HTTP/1.1 200 OK
X-Powered-By: Express
Content-Type: text/html; charset=utf-8
Content-Length: 202
Connection: keep-alive
<!DOCTYPE html>
<html>
<head>
<title>Express</title>
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
<body>
<h1>Express</h1>
<p>Welcome to Express</p>
</body>
</html>
浏览器在接收到内容以后,经过分析发现要获取/stylesheets/style.css,因此会再次向服务器发起请求。app.js 中并没有一个路由规则指派到 /stylesheets/style.css,但 app 通过app.use(express.static(__dirname + ‘/public’)) 配置了静态文件服务器,因此/stylesheets/style.css 会定向到 app.js所在目录的子目录中的文件public/stylesheets/style.css,向客户端返回以下信息:
HTTP/1.1 200 OK
X-Powered-By: Express
Date: Mon, 02 Apr 201215:56:55 GMT
Cache-Control: public,max-age=0
Last-Modified: Mon, 12Mar 2012 12:49:50 GMT
ETag: "110-1331556590000"
Content-Type: text/css;charset=UTF-8
Accept-Ranges: bytes
Content-Length: 110
Connection: keep-alive
body {
padding: 50px;
font: 14px "LucidaGrande", Helvetica, Arial, sans-serif;
}
a {
color: #00B7FF;
}
由 Express 创建的网站架构如下图所示。
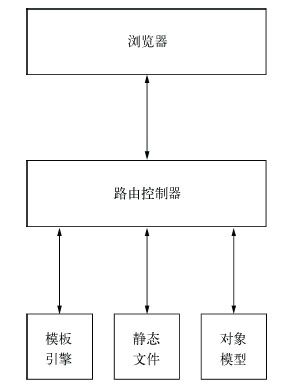
这是一个典型的MVC 架构,浏览器发起请求,由路由控制器接受,根据不同的路径定向到不同的控制器。控制器处理用户的具体请求,可能会访问数据库中的对象,即模型部分。控制器还要访问模板引擎,生成视图的HTML,最后再由控制器返回给浏览器,完成一次请求。 node.js plugin(with C++)
Node.js的许多插件是用C/C++来写的,其官方api中给出了addon的相关说明,http://nodejs.org/api/addons.html,虽然项目最终没有用上这一方面的东西,但是我觉得这块的知识还是挺重要的,它涉及到node.js和C/C++的集成。
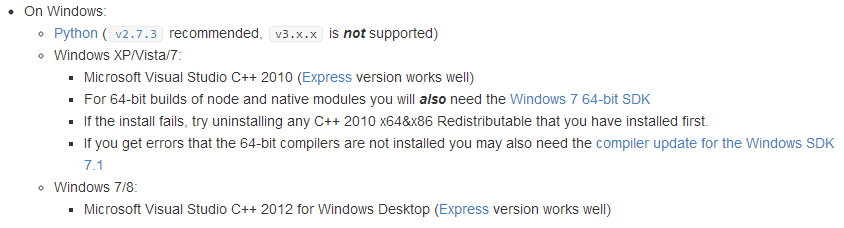
需要特别强调的是,在window下用node-gyp来build相关C++代码的时候,前期环境的配置很重要,在这一块我走了很多弯路,最终导致我的工作机不能安装Microsoft Visual Studio C++ 2010,最后不得不用自己的电脑来测试。在window下,相关的配置工作如下:
参考文献:
-
node.js开发指南